#### 回到 [`教學大綱`](https://md.kingkit.codes/s/siSKyknlU)
<style>
blockquote.announcement {
background-color: #f4aa14;
height: 50px;
width: 100%;
display: flex;
justify-content: center;
border-left: none;
}
blockquote.announcement p {
color: white;
height: 100%;
align-items: center;
display: flex;
}
.announcement a {
background-color: rgba(0, 0, 0, 0.2);
text-decoration: none;
padding: 6px 16px;
border: 1px;
border-radius: 8px;
color: #fff;
line-height: 30px;
}
</style>
<blockquote class="announcement">
<p>
Webduino 學習手冊網站即將改版,提供您更好的閱讀體驗!<a
href="https://resource.webduino.io/docs/webai"
target="_blank"
rel="noopener"
>搶先試用</a
>
</p>
</blockquote>
# 三、影像訓練
Web:AI 影像辨識可以使用 Web:AI 開發板拍攝影像上傳至 Webduino 影像訓練平台進行影像訓練,將訓練完成的模型下載,再使用程式積木執行影像辨識。
## 影像辨識流程
進行影像辨識的流程中,需要先**分別建立影像分類**,接著**選擇要建立的模型種類 ( 影像分類、物件追蹤 )**,並**將分類放入模型中**,就可以使用模型來進行影像辨識了。
## A. 登入影像訓練平台
1. 點擊連結進入 [Webduino 影像訓練平台](https://vision.webduino.io)。
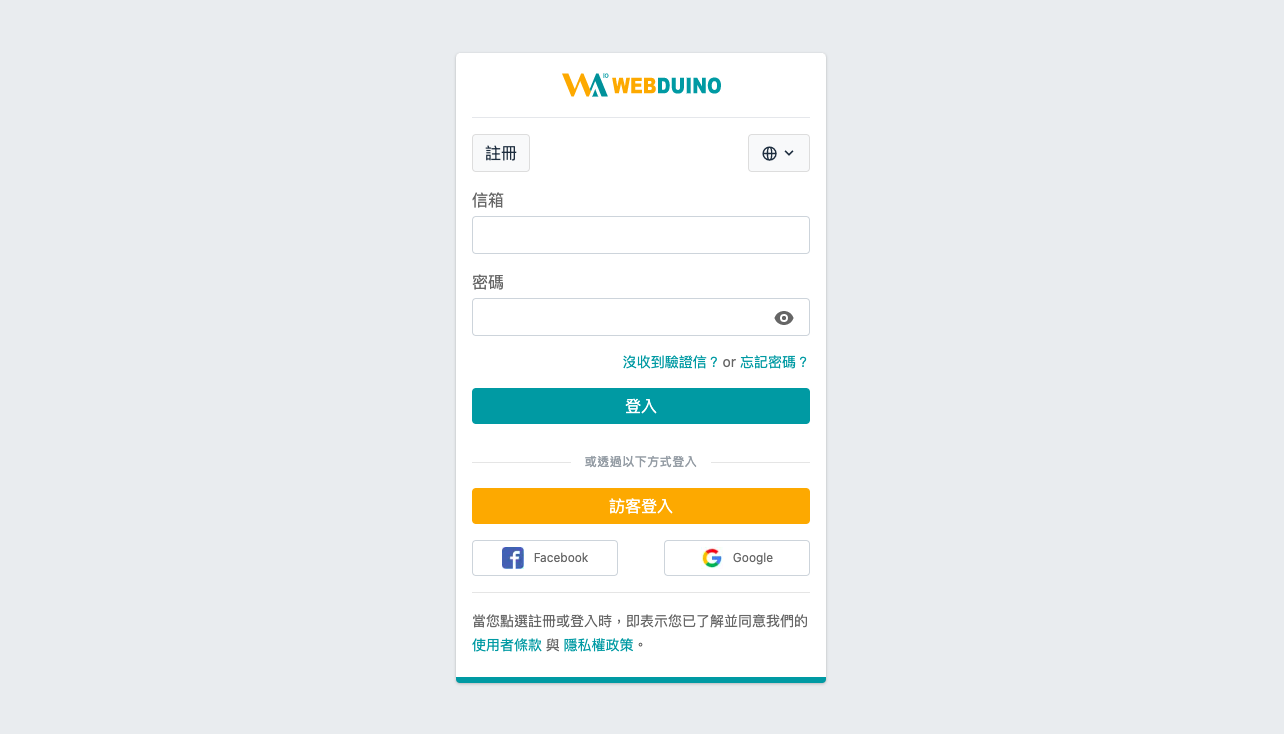
2. 選擇登入方式或註冊帳號。
「訪客登入」會和其他訪客共用分類和模型,為避免被刪除或修改,建議使用自己的帳號登入。
3. 登入成功後,進入 Webduino 影像訓練平台。
## B. 建立分類
1. 在 Webduino 影像訓練平台中可以看到左側的側邊欄有「分類」和「模型」兩個選項,點擊「分類」進入分類列表。

2. 點擊藍色「新增」按鈕,跳出「建立分類」視窗。
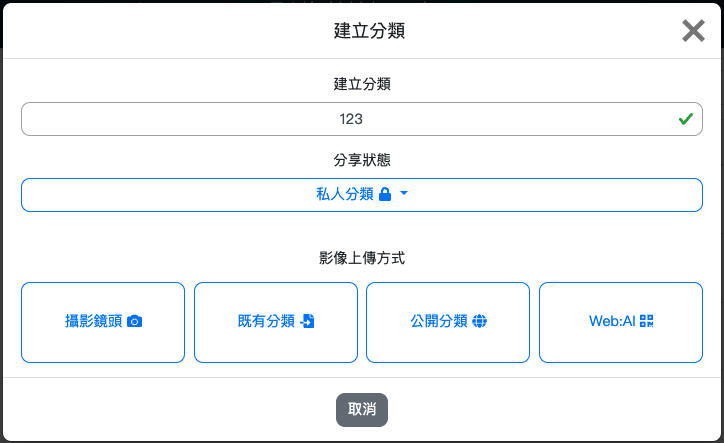
- 輸入分類名稱,<span style="color: red;">請勿輸入中文、空格、符號</span>
- 選擇分享狀態
- 影像上傳方式點選「Web:AI」,進入下一步

- 輸入要拍照的數量 ( 15 ~ 20 張 )
- 輸入 Web:AI 開發板的 DeviceID <span style="color: red;">( 請確認 Web:AI 已連上 Wi-Fi )</span>
- 選擇是否旋轉鏡頭
- 是:使用後鏡頭 ( 鏡頭在螢幕背面 )
- 否:使用前鏡頭 ( 鏡頭和螢幕在同一側 )
> 目前因為鏡頭旋轉功能外殼尚未上市,因此旋轉鏡頭選項**不需勾選**,敬請期待!
3. 點擊「建立分類」按鈕

4. 看到「傳送指令成功」訊息,就可以開始使用 Web:AI 開發板拍照。
## C. 使用開發板拍攝影像
傳送指令成功後,開發板會重新啟動,進入拍照模式。
### 拍照模式
- 左上角白色數字:目前拍照張數
- L 按鈕:拍攝照片
- R 按鈕:調整白框大小
- 中間白色方框:拍照時,讓拍攝物件跟方框相當大小
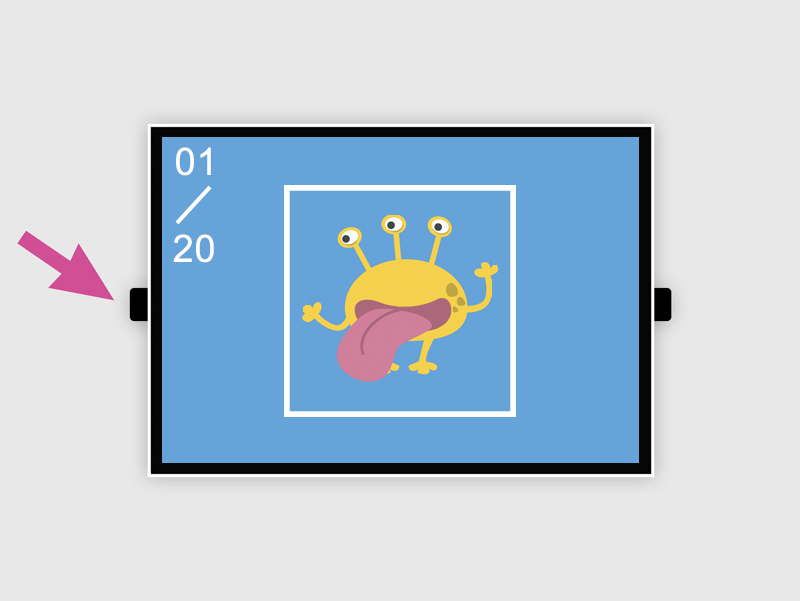
當**拍攝物件跟方框相當大小**時按下 **L 按鈕** 拍攝,並且稍微轉動角度,拍攝不同角度影像。
### 上傳影像
1. 拍完設定的照片數量後,畫面會變全黑,開始上傳圖片。

2. 等待上傳完成後,畫面中央會顯示白色 ok,正下方顯示上傳時間。

3. 點擊視窗中的 ✕ 或「回到主畫面」,將視窗關閉。
### 建立 2~4 個分類
進行影像辨識時,模型內需要放入 2~4 個分類才能進行辨識,
因此重複上述 **建立分類**、**使用開發板拍攝影像** 步驟,建立兩個以上的分類。
## D. 建立模型
1. 建立完分類後,在左側的側邊欄選擇「模型」,進入模型列表。

2. 點擊藍色「新增」按鈕,跳出「新增模型」視窗。( 下圖以影像分類為例 )
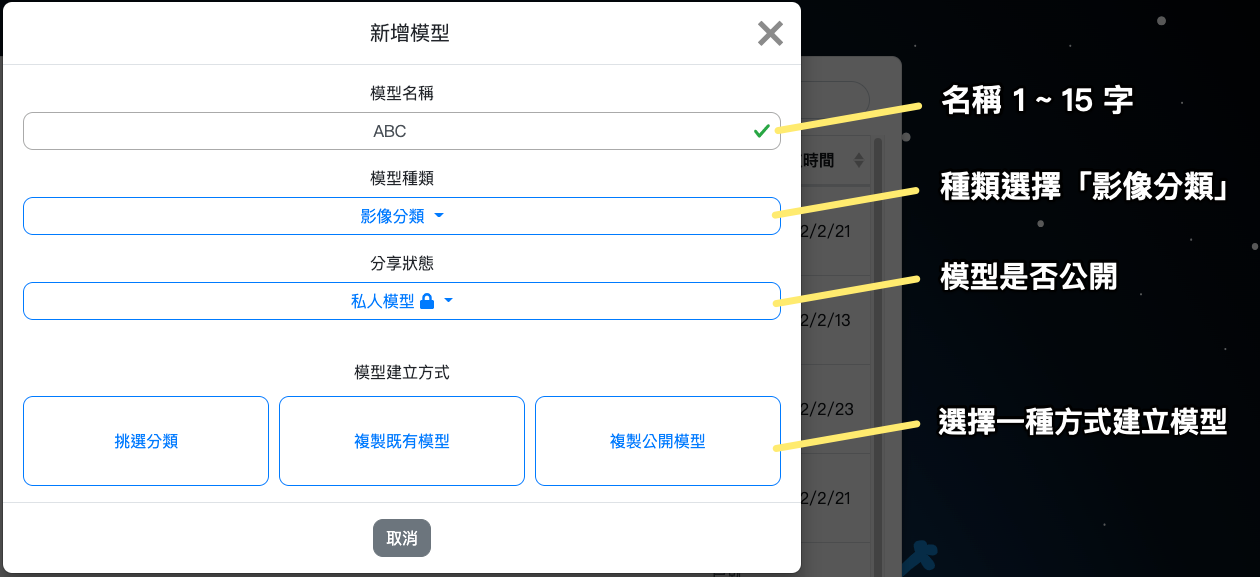
- 輸入模型名稱,**請勿輸入中文、空格、符號或使用過的名稱**
- 選擇模型種類 ( 影像分類、物件追蹤 )
- 選擇分享狀態
- 模型建立方式點選「挑選分類」
3. 從分類列表中點選 2~4 個要進行影像辨識的分類,點擊「建立模型」。
- 影像分類:請選最少 2 個分類,最多 4 個分類。
- 物件追蹤:請選最少 2 個分類,最多 5 個分類。
> <span style="color: red;">為確保模型訓練品質,請選擇 15 張圖片以上的分類。</span>

4. 訓練中的模型會顯示訓練進度百分比,等待模型訓練完成後,就可以在模型列表中找到建立的模型,並且可以看到模型內的**分類名稱**以及**模型種類**。
> 模型訓練時,全平台限制 30 個模型同時訓練,若數量已達限制,請稍待 1 ~ 2 分鐘再重新嘗試。

## E. 下載模型
1. 點擊要進行影像辨識的模型,跳出「模型選項」視窗。
a. 點擊下載模型。

b. 輸入開發板 Device ID。<span style="color: red;">( 請確認 Web:AI 已連上 Wi-Fi )</span>

c. 點擊「下載模型」後傳送指令。

2. 點擊「下載模型」按鈕,出現「傳送指令成功」訊息即開始下載模型。

3. 完成 100% 後,畫面會顯示 **ok** 字樣代表完成下載,部署程式積木後,就可以開始進行影像辨識了。
## F. 使用程式積木執行影像辨識
在 [Web:AI 程式積木平台](https://webai.webduino.io/#/) 中,可以使用「影像分類」或「物件追蹤」積木,來進行影像辨識。
### 影像分類
- 有關詳細積木的使用,歡迎參考:[影像分類](https://md.kingkit.codes/s/XsGqYu8lP)。
1. 先依照上面步驟,將訓練過的影像分類模型下載到 Web:AI 開發板中。
> 本篇以模型「Monster」,分類「blue,green,yellow,red,」為例。
2. 開啟 [Web:AI 程式積木平台](https://webai.webduino.io/#/) 。
3. 點擊上方主功能選單中的「範例」。
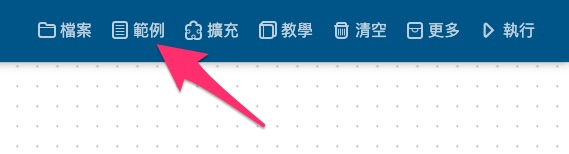
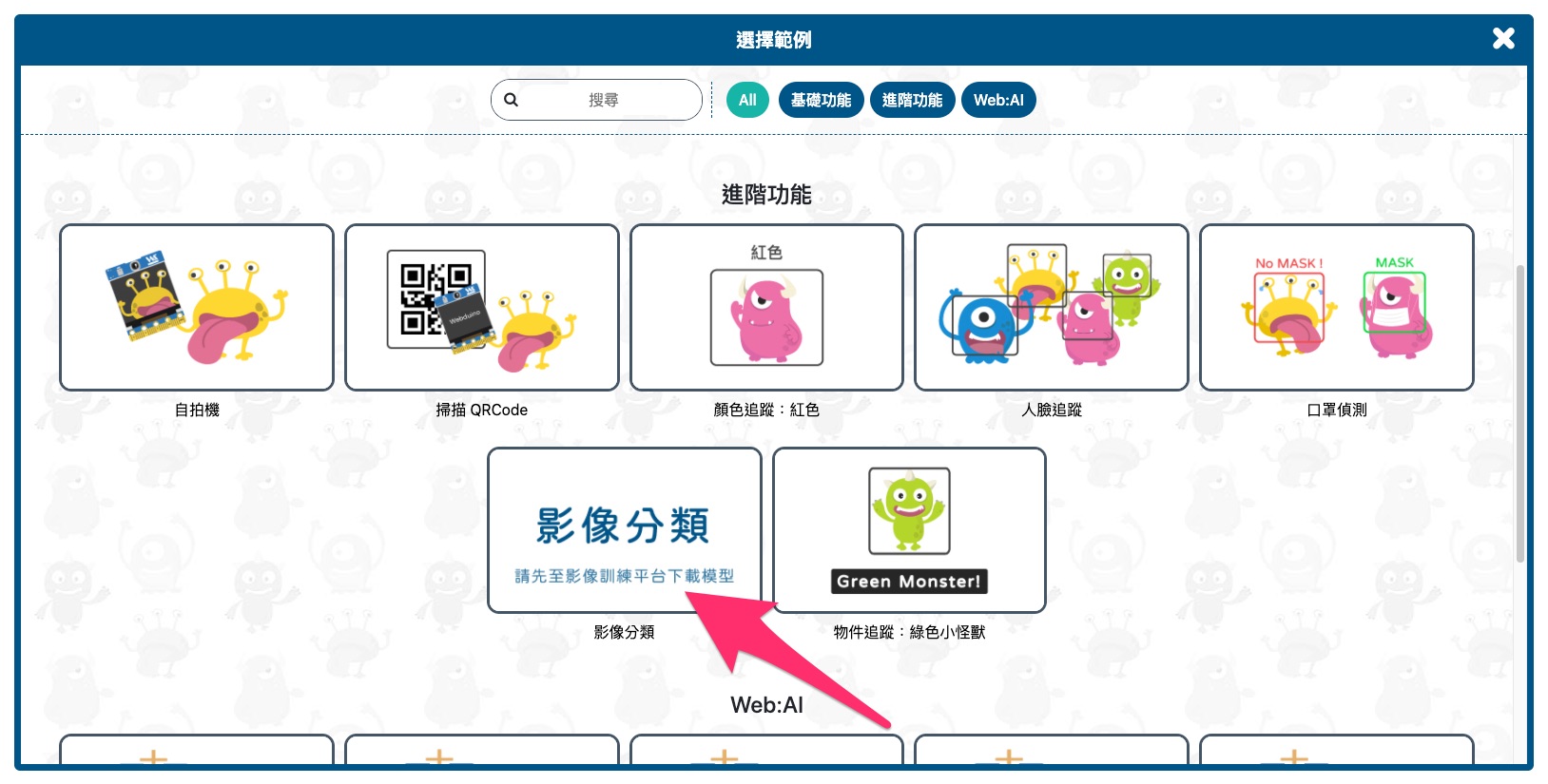
4. 開啟後,點擊「進階功能」中的「影像分類」,開啟影像分類範例程式。
5. 在「設定模型」積木中選擇模型;
如果是使用 **安裝版程式平台**,則需要手動輸入模型、分類,並將寬、高都輸入 224。
>- 使用 Webduino 影像訓練平台訓練的模型尺寸,為 224*224。
>- 自行使用其它工具訓練,則需輸入各別的尺寸。
下圖範例選擇模型「Monster」,分類「blue,green,yellow,red」。

6. 程式編輯完成後,按下右上角「執行」按鈕,程式部署結束後 Web:AI 開發板會自動開啟鏡頭畫面。
7. 使用鏡頭對準辨識物件就能看到文字顯示辨識結果和信心度。

> 若要使用其它模型來進行影像辨識,需要回到步驟 **下載模型**,再次下載模型。
### 物件追蹤
- 有關詳細積木的使用,歡迎參考:[物件追蹤](https://md.kingkit.codes/s/BrL3wxxd_)。
1. 先依照上面步驟,將訓練過的物件追蹤模型下載到 Web:AI 開發板中。
> 本篇以模型「Monster」,分類「green,yellow,red,blue」為例。
2. 開啟 Web:AI 程式積木平台。
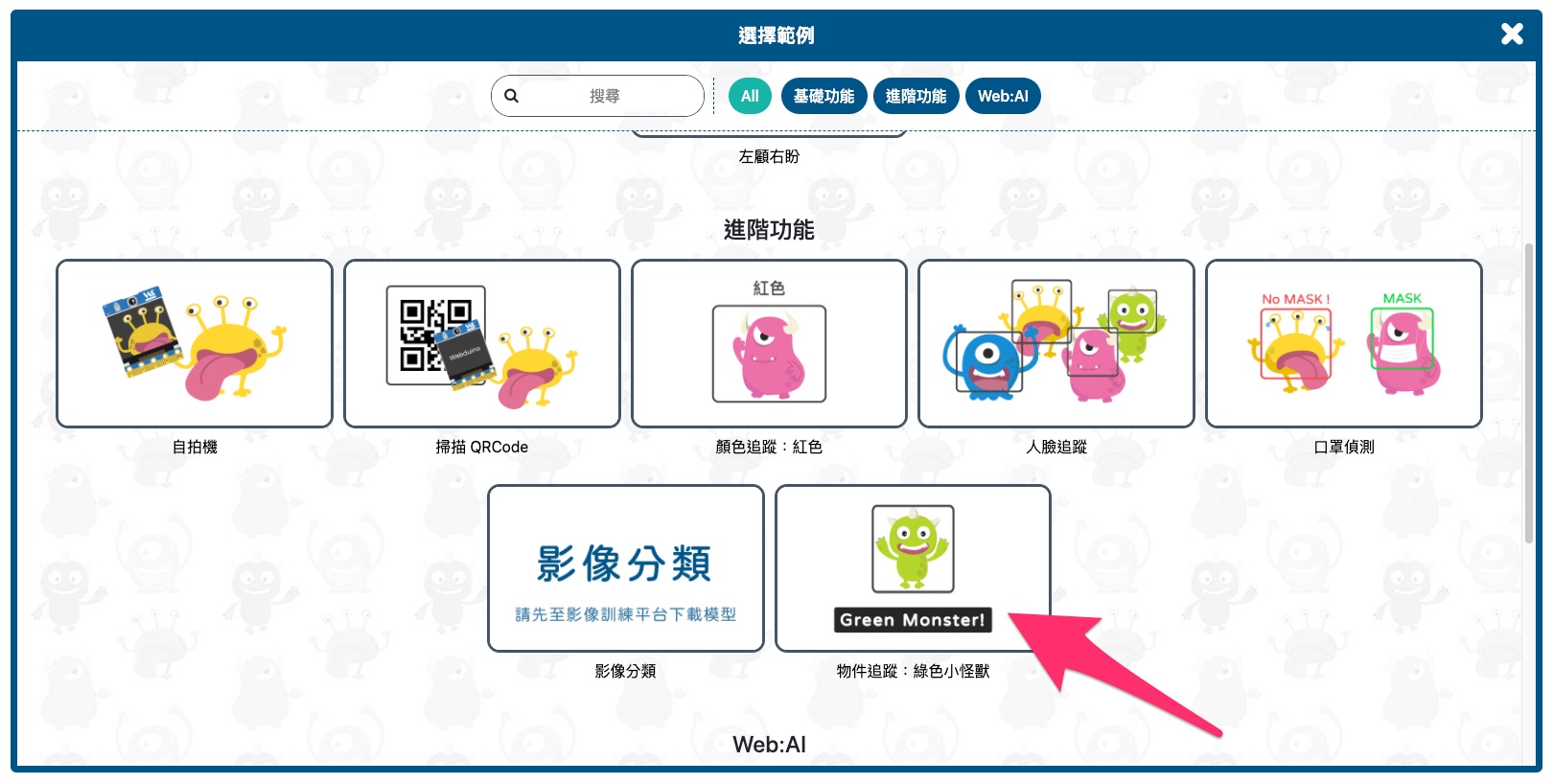
3. 點擊上方主功能選單中的「範例」。

4. 開啟後,點擊「進階功能」中的「物件追蹤:綠色小怪獸」,開啟物件追蹤範例程式。
> 範例「物件追蹤:綠色小怪獸」原本使用的模型是內建的小怪獸模型,因為要使用下載模型,所以需要對程式設定作修改。
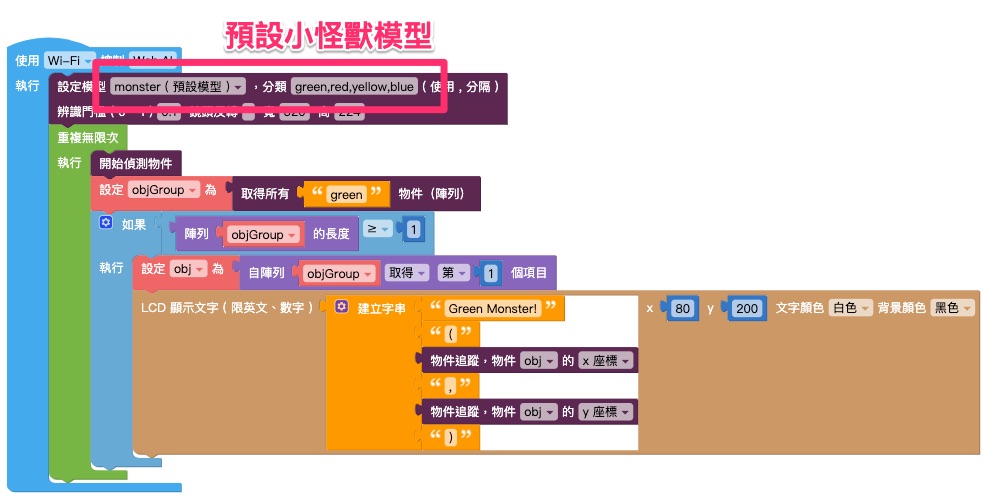
5. 在「設定模型」積木中選擇模型;
如果是使用 **安裝版程式平台**,則需要手動輸入模型、分類,並將寬、高都輸入 224。
>- 使用 Webduino 影像訓練平台訓練的模型,尺寸為 224*224。
>- 使用內建小怪獸模型,尺寸為 320*224。
>- 自行使用其它工具訓練,則需輸入各別的尺寸。
下圖範例選擇模型「Monster」,分類「green,yellow,red,blue」。

6. 修改「取得所有物件」積木和要顯示的資訊,將範例程式改成模型中的其中一個分類,讓程式可以顯示分類的相關資訊。
下圖範例程式會顯示分類「yellow」的資訊。
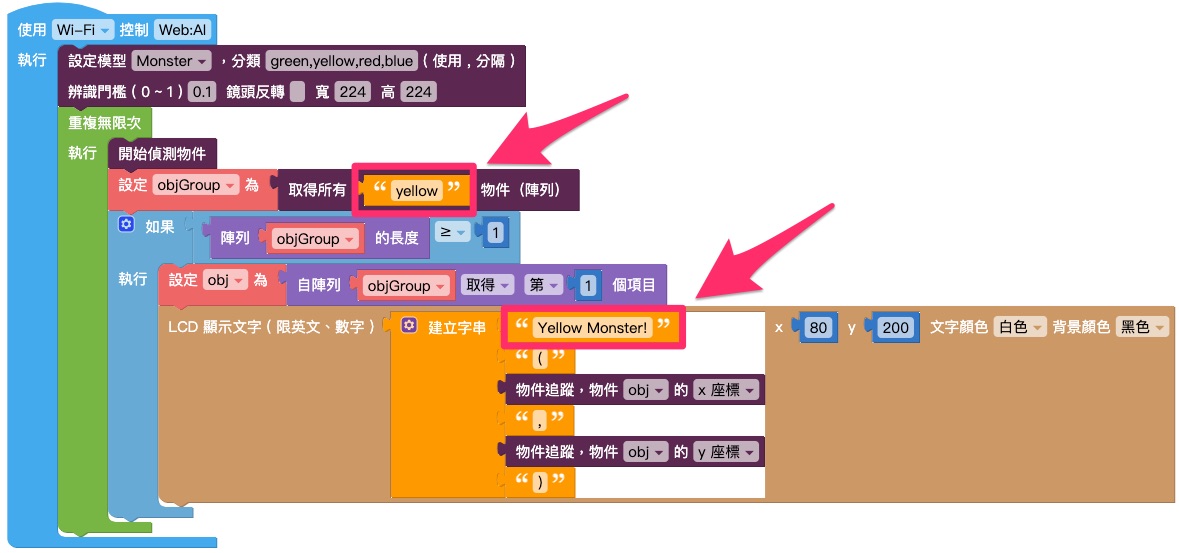
7. 程式編輯完成後,按下右上角「執行」按鈕,程式部署結束後 Web:AI 開發板會自動開啟鏡頭畫面。
8. 使用鏡頭對準辨識物件就能看到白框顯示辨識結果和座標。
如範例顯示「Yellow Monster!(168,137)」。

### ?♀️ 如何提高「物件追蹤」模型辨識的準確度?
訓練好的模型辨識不出物體,或是誤判怎麼辦呢?不妨試試下面的方法:
1. 每個分類照片數量越多,訓練出來模型準確度會越高。若使用電腦鏡頭拍攝照片,盡量上傳達 30 張。若使用 Web:AI 鏡頭拍攝,則盡量上傳達 20 張。
2. 拍攝建立分類時,掌握以下拍攝技巧:
- 若使用電腦鏡頭拍攝照片,請將物體靠近鏡頭,直到物體與鏡頭預覽的方框切齊。若使用 Web:AI 鏡頭拍攝,請確保物體與螢幕上的白色方框切齊。
電腦鏡頭

Web:AI 鏡頭

- 若使用 Web:AI 鏡頭拍攝,同一個分類盡量選用固定大小的白色方框 ( 開發板 R 鍵可以切換方框大小,共有 5 種大小,任選一種使用即可 )。
- 原則上拍攝物體的背景越多樣化,效果越好,因此拍攝時可以將物體擺在不同背景前拍攝,最簡單的方式就是人站在原地旋轉拍攝。若發現辨識效果不如預期,可以改為較單純的背景拍攝 ( 例如:牆壁、天花板、桌面 )。
- 拍攝時,盡量確保鏡頭方框內只有要辨識的物體,非辨識物體 ( 例如:人臉、手掌 ) ,不要進到畫面內。
- 確保同一個分類內,包含物體不同角度的照片。建議拍攝物體左傾、水平、右傾三個角度,各至少 6~8 張。
- 確保在光線充足的環境拍攝照片,且避免物體背光。
4. 辨識物體間的差異越大,辨識的效果越好。因此在挑選用來訓練模型的分類時,可以盡量選擇「顏色」、「形狀」差異大的物體。
5. 在 [Web:AI 程式積木平台](https://webai.webduino.io/#/) 編輯程式時,留意「物件追蹤」積木上的「辨識門檻」。

辨識門檻代表物件追蹤的精準度,門檻越高代表偵測到的物體外觀與模型越接近,才會辨識成功,預設為 0.5。
測試時,若覺得辨識結果誤判的機率較高( 例如:畫面上沒有物體 A,卻辨識出 A ),可逐步調高辨識門檻,直到辨識結果符合預期。
> 有關詳細積木的使用,歡迎參考:[物件追蹤](https://md.kingkit.codes/s/BrL3wxxd_)。